






( 10 Students )


JanusGraph
Master JanusGraph from scratch and build scalable, distributed graph applications using Apache TinkerPop and Gremlin with deployment strategies.Preview JanusGraph course
Price Match Guarantee Full Lifetime Access Access on any Device Technical Support Secure Checkout Course Completion Certificate 91% Started a new career
BUY THIS COURSE (
91% Started a new career
BUY THIS COURSE (GBP 10 GBP 29 )-
 82% Got a pay increase and promotion
82% Got a pay increase and promotion
Students also bought -
-
- Neo4j
- 10 Hours
- GBP 10
- 10 Learners
-

- Amazon Neptune
- 10 Hours
- GBP 10
- 10 Learners
-

- TigerGraph
- 10 Hours
- GBP 10
- 10 Learners

- Set up and configure your JanusGraph environment securely for development and distributed deployment.
- Design optimal graph schemas to represent complex relationships and data.
- Master the Gremlin graph traversal language for all aspects of graph data manipulation and analysis.
- Perform deep link analytics to uncover hidden patterns and insights within interconnected data.
- Implement common graph algorithms (e.g., shortest path, community detection, PageRank) using Gremlin and external libraries.
- Efficiently load and manage large datasets within JanusGraph.
- Integrate JanusGraph with external applications using TinkerPop drivers and REST APIs.
- Optimize Gremlin traversals for maximum performance and scalability.
- Choose and configure appropriate storage and indexing backends (Cassandra, HBase, Elasticsearch).
- Generate meaningful insights from graph data to solve real-world business problems.
- A knowledge graph implementation for managing and querying interconnected enterprise data.
- A fraud detection system identifying suspicious patterns in financial transactions.
- A social network analysis platform to understand community structures and influence.
- A master data management solution leveraging graph capabilities for data lineage and relationships.
- Model complex relationships effectively using graph structures.
- Write powerful Gremlin traversals for deep link analytics.
- Implement and customize graph algorithms for various use cases.
- Optimize distributed graph database performance for real-time applications.
- Integrate graph insights into existing data pipelines and applications.
- Develop professional graph solution designs with actionable recommendations.
- Aspiring Graph Data Scientists who want to specialize in powerful relationship analysis.
- Data Engineers and Architects looking to incorporate scalable graph databases into their data ecosystems.
- Backend Developers building applications that leverage highly connected, distributed data.
- Students and Beginners in database technologies looking for a structured and approachable course in distributed graph databases.
- Tech Professionals aiming to understand advanced data modeling and analytics.
- Entrepreneurs and Freelancers who want to build data-driven applications with deep insights using open-source technologies.
- Follow the Sequence The course is designed to build progressively on knowledge. Start from the first module and move forward in order. Each concept introduces new techniques while reinforcing previously learned skills. Skipping ahead may cause confusion later, especially in projects that require cumulative understanding.
- Build Alongside the Instructor Hands-on practice is essential. As you watch the video tutorials, execute the Gremlin commands and configure JanusGraph in your own environment (local, Docker, or cloud-based setup with chosen backends recommended). Don’t just observe—type the commands yourself, experiment with variations, and troubleshoot errors. This repetition will solidify your learning and build real-world problem-solving skills.
- Use the Projects as Practice and Portfolio Pieces Each project you build during the course has real-world value. Customize them, add your own features, and consider documenting your solutions for a portfolio. These projects can become part of your portfolio when applying for data science or engineering jobs.
- Take Notes and Bookmark Key Concepts Keep a graph database journal. Write down important Gremlin syntax, schema design patterns, backend configurations, and lessons learned. Bookmark the modules covering key concepts like distributed deployment, complex querying, or performance optimization for quick reference.
- Utilize the Community and Support Resources If the course offers a discussion forum, Slack group, or Q&A section, use it! Ask questions when you're stuck and help others when you can. Participating in a community will deepen your understanding and expose you to diverse perspectives and solutions.
- Explore Apache TinkerPop and JanusGraph Documentation JanusGraph and Apache TinkerPop have extensive official documentation. You’re encouraged to explore it further, especially the Gremlin language reference and backend-specific configurations. Developing the habit of reading official documentation will make you a more independent and resourceful graph database professional.
- Experiment with Different Storage and Indexing Backends JanusGraph's flexibility in choosing backends is a major strength. If possible, try setting up JanusGraph with different storage (e.g., Cassandra, HBase) and indexing (e.g., Elasticsearch) backends to understand their configuration and performance characteristics.
- Review and Revisit Distributed graph database development is a skill built through repetition and iteration. Don’t be afraid to revisit previous lessons or re-implement a graph solution from scratch. Each time you do, you’ll catch something new or improve your understanding and efficiency.
Course/Topic 1 - Coming Soon
-
The videos for this course are being recorded freshly and should be available in a few days. Please contact info@uplatz.com to know the exact date of the release of this course.
- Understand the fundamental architecture and components of the JanusGraph database.
- Choose, configure, and integrate various storage backends (e.g., Cassandra, HBase) and indexing backends (e.g., Elasticsearch, Solr) with JanusGraph.
- Design effective graph schemas using property keys, vertex labels, edge labels, and composite/mixed indexes for different data models.
- Master the Gremlin graph traversal language for all data manipulation (CRUD) and complex query operations.
- Write sophisticated Gremlin traversals for advanced pattern matching, aggregations, and multi-hop relationships.
- Implement common graph algorithms such as Shortest Path, PageRank, and Community Detection using Gremlin.
- Perform efficient data loading into JanusGraph from various sources, including CSV and custom scripts.
- Optimize Gremlin traversals and JanusGraph configurations for high performance and scalability in distributed environments.
- Interact with JanusGraph programmatically using Apache TinkerPop Java, Python, and other language drivers.
- Understand and apply best practices for deploying, monitoring, and administering JanusGraph clusters.
- Troubleshoot common issues related to JanusGraph setup, data loading, and query performance.
- Articulate the advantages of JanusGraph for enterprise-scale graph database solutions.
- What are Graph Databases? (Review of concepts)
- Introduction to Apache TinkerPop and the Gremlin Ecosystem
- Why JanusGraph? Features, Architecture, and Use Cases
- Setting Up Your JanusGraph Environment (Local, Docker, Basic Distributed)
- Overview of Storage Backends (Cassandra, HBase, Google Cloud Bigtable, BerkeleyDB)
- Overview of Indexing Backends (Elasticsearch, Apache Solr, Apache Lucene)
- Configuring JanusGraph with Cassandra/HBase (as primary examples)
- Configuring JanusGraph with Elasticsearch/Solr (as primary examples)
- Defining Property Keys, Vertex Labels, and Edge Labels
- Cardinality and Data Types
- Creating Indexes (Graph Indexes, Mixed Indexes)
- Schema Management and Evolution
- Introduction to Gremlin Console
- Adding Vertices and Edges
- Adding Properties to Vertices and Edges
- Updating and Deleting Graph Elements
- Basic Gremlin Traversal Syntax (g.V(), g.E(), has(), values())
- Multi-hop Traversals (repeat(), times(), until())
- Filtering Data (where(), and(), or())
- Aggregations (count(), sum(), group(), groupCount())
- Path Traversals (path(), simplePath())
- Branching and Conditional Logic (choose(), union())
- Strategies for Loading Data into JanusGraph
- Using Gremlin for Batch Loading
- Introduction to Spark-Gremlin for Bulk Loading
- Monitoring and Error Handling during Loads
- Implementing Shortest Path Algorithm
- PageRank Algorithm
- Community Detection (e.g., Connected Components)
- Integrating with Graph Algorithms Libraries (if applicable)
- Using Apache TinkerPop Drivers (Java, Python)
- Connecting via Gremlin Server
- Overview of REST APIs for Graph Interaction
- Building Simple Client Applications
- Optimizing Gremlin Traversals
- Schema Design for Performance
- Index Strategy and Tuning
- Understanding Query Execution Plans
- JanusGraph Cluster Deployment Concepts
- Monitoring JanusGraph with Metrics
- Backup and Restore Strategies
- Scalability, High Availability, and Fault Tolerance
- Building a Knowledge Graph
- Fraud Detection System Architecture
- Supply Chain Optimization
- Customer 360 View
- Implementing a Social Network Graph with Follower Analysis
- Building an Enterprise Master Data Management Graph
- Developing a Recommendation Engine based on Product Relationships
- Designing a Cybersecurity Threat Intelligence Graph
- Fraud Ring Detection System
- Drug Discovery Knowledge Graph
- Supply Chain Resilience Analysis
- Customer Journey Mapping
- Network Topology Visualization
- Top Interview Questions for Graph Database and JanusGraph Roles
- Best Practices and Explanations
- Graph Data Scientist
- Data Engineer (Distributed Graph Databases)
- Solution Architect (Graph Databases)
- Backend Engineer (Graph-enabled applications)
- Big Data Engineer
- Database Administrator (Graph Focus)
1. What is JanusGraph, and what are its key architectural components? JanusGraph is an open-source, distributed graph database optimized for storing and querying large-scale graphs. Its key components include:
o Graph API: Implements Apache TinkerPop's Graph interface.
o Storage Backends: Stores the graph data (e.g., Apache Cassandra, Apache HBase, Google Cloud Bigtable, Oracle Berkeley DB).
o Indexing Backends: Provides search capabilities for properties and vertices (e.g., Elasticsearch, Apache Solr, Apache Lucene).
o Gremlin: The graph traversal language for querying and manipulating data.
2. Explain the role of Apache TinkerPop and Gremlin in JanusGraph. Apache TinkerPop is a graph computing framework that defines a standard set of interfaces and processes for graph databases. JanusGraph implements these interfaces, making it compatible with the TinkerPop ecosystem. Gremlin is the graph traversal language provided by TinkerPop, used to query, manipulate, and analyze data within JanusGraph.
3. How do you choose between different storage backends for JanusGraph? The choice of storage backend depends on specific requirements:
o Apache Cassandra: Ideal for write-heavy workloads, linear scalability, and high availability across data centers.
o Apache HBase: Suitable for random read/write access, strong consistency, and integration with the Hadoop ecosystem.
o Google Cloud Bigtable: A managed service offering similar characteristics to HBase, good for cloud-native deployments.
o Oracle Berkeley DB: Embedded, single-node backend suitable for small-scale applications or development.
4. Describe the different types of indexes in JanusGraph and when to use them. JanusGraph supports two main types of indexes:
o Graph Indexes (Vertex-centric/Edge-centric): Automatically created and maintained by JanusGraph, used for speeding up graph traversals (e.g., has(key, value)). Best for exact matches.
o Mixed Indexes (Global Graph Indexes): Backed by external indexing services (Elasticsearch, Solr), used for complex queries like text search, range queries, or fuzzy matches across multiple properties.
5. How do you add schema constraints in JanusGraph? Schema constraints (like uniqueness for property keys or labels) are defined programmatically using the JanusGraph Management API. For example, to ensure a username property is unique for a User vertex, you would define schema.makePropertyKey('username').dataType(String.class).single().make() and schema.makeVertexLabel('User').make().
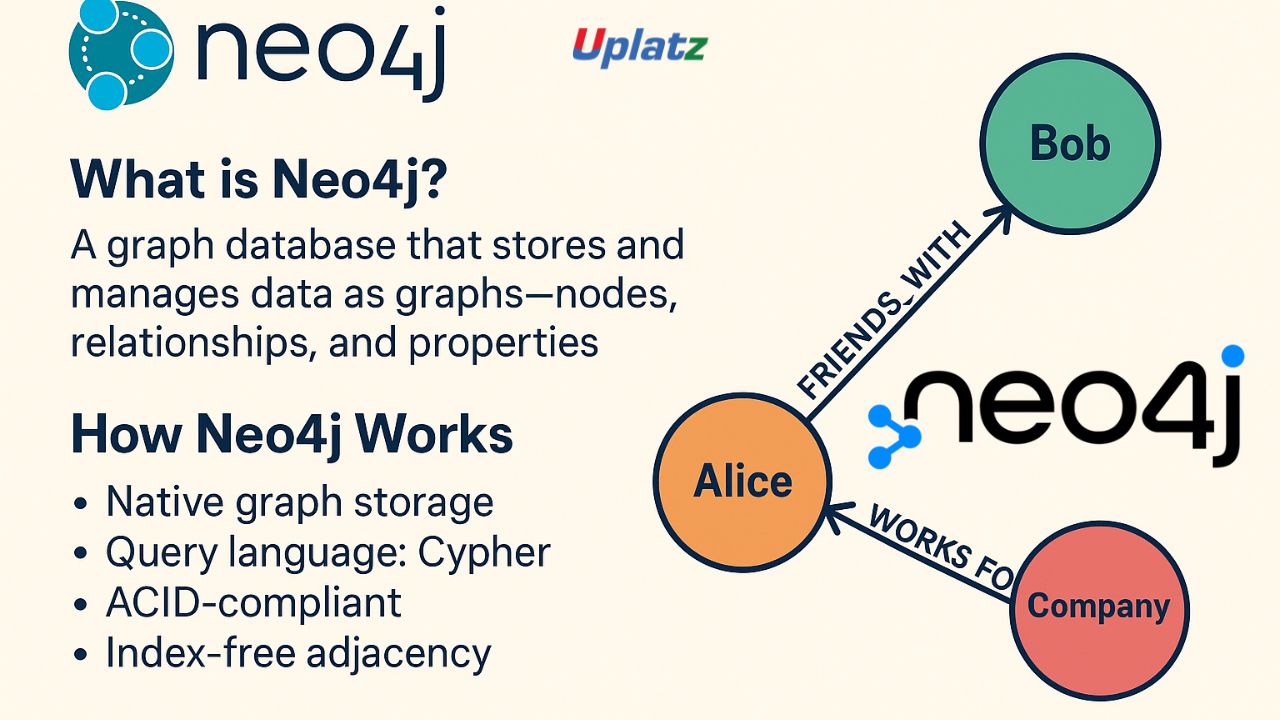
6. Provide a simple Gremlin traversal to find all friends of a person named "Alice" in a social graph. Assuming Person vertices have a name property and are connected by friend edges: g.V().has('Person', 'name', 'Alice').out('friend').values('name')
7. What are the challenges of managing a distributed JanusGraph cluster? Challenges include:
o Backend Management: Managing the underlying distributed storage (Cassandra/HBase) and indexing (Elasticsearch) clusters.
o Data Consistency: Ensuring consistency across distributed nodes.
o Fault Tolerance: Designing for redundancy and graceful degradation.
o Performance Tuning: Optimizing queries and cluster configuration for large-scale data.
o Monitoring and Logging: Centralized monitoring of all components.
8. How can you load large datasets into JanusGraph efficiently? For large datasets, using bulk loading mechanisms is crucial:
o Spark-Gremlin: The recommended tool for large-scale parallel loading. It integrates Apache Spark with TinkerPop for efficient ETL.
o Batch Gremlin: Using g.addV() and g.addE() within a transaction or batch processing.
o JanusGraph's GraphFactory: Can configure a BulkLoad option for optimized loading.
9. Explain the difference between single() and multiple() property cardinalities in JanusGraph schema.
o single(): A property key can have at most one value for a given vertex or edge. This is the default.
o list(): A property key can have multiple values for a given vertex or edge, and the order of values is preserved.
o set(): A property key can have multiple values for a given vertex or edge, but each value must be unique, and the order is not preserved.
10. What is an example of a real-world application where JanusGraph would be a suitable choice? A suitable application is Master Data Management (MDM). JanusGraph excels at MDM by representing master data entities (e.g., customers, products, locations) as vertices and their relationships (e.g., "owns", "locatedAt", "composedOf") as edges. This allows organizations to establish a single, interconnected source of truth, resolve data discrepancies, and visualize complex data lineage across various systems. Its scalability handles large datasets, and Gremlin allows for complex queries to understand how data entities are related and consistent.